


| Dr Evrim Acar, University of Copenhagen, Denmark |
| Thu 17 Mar 2016, 13:00 - 14:00 |
| AGB Seminar Room, AGB Building, King’s Buildings, EH9 3JL |
If you have a question about this talk, please contact: Iman Tavakkolnia (s1371647)
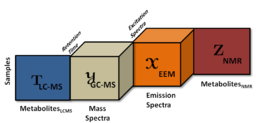
Abstract: In the era of data science, it no longer suffices to analyze a single data set if the goal is to unravel the dynamics of a complex system such as the human metabolism. The complexity of such problems has brought out the necessity of data collection from multiple sources. Therefore, data fusion, i.e., extracting knowledge through the fusion of complementary data sets, is a topic of interest in many fields. For instance, in metabolomics, analytical platforms such as Liquid Chromatography-Mass Spectrometry (LC-MS) and Nuclear Magnetic Resonance (NMR) spectroscopy are used for chemical profiling of biological samples. Measurements from different platforms are capable of detecting different types of chemical compounds with different levels of sensitivity. Fusing data from multiple sources has proved useful in various disciplines including metabolomics, neuroscience, social network analysis and signal processing. However, data fusion remains a challenging task since there is a lack of data mining tools that can jointly analyze imperfect (i.e., with missing entries) heterogeneous (i.e., in the form of higher-order tensors and matrices) data sets, and capture underlying shared/unshared structures. We formulate data fusion as a coupled matrix and tensor factorization (CMTF) problem and discuss its extension to structure-revealing data fusion, i.e., fusion models that can identify shared and unshared factors. In order to solve the coupled factorization problem, we use an all-at-once optimization approach, which easily extends to coupled analysis of incomplete data sets. Numerical experiments on simulated and experimental coupled data sets demonstrate that while traditional methods based on matrix factorizations have limitations in terms of jointly analyzing heterogeneous data sets, the structure-revealing CMTF model can successfully capture the underlying factors by exploiting the low-rank structure of higher-order data sets.
Short Bio: Evrim Acar is an Assistant Professor in the Spectroscopy and Chemometrics group at the Faculty of Science at the University of Copenhagen. She received her B.S. degree in Computer Engineering from Bogazici University (Istanbul, Turkey) in 2003, and her M.S. and Ph.D. degrees in Computer Science from Rensselaer Polytechnic Institute (Troy, NY) in 2006 and 2008, respectively. Prior to joining the University of Copenhagen, she was a postdoctoral researcher at Computational Sciences and Mathematics Research Department at Sandia National Laboratories in Livermore, CA, and a senior researcher at the National Research Institute of Electronics and Cryptology in Turkey. Her research focuses on data mining, in particular, tensor factorizations (multi-way data analysis) and their applications in biomedical computing and social network analysis.